Data Collaboratives: Exchanging Data to Improve People’s Lives
By Stefaan Verhulst and David Sangokoya, The GovLab
In late July 2014, a sick passenger from Liberia traveled to Nigeria and brought the Ebola virus to Lagos, Africa’s largest city, with a population of 21 million. In response, government agencies, universities and hospitals collaborated with private telecommunications companies and healthcare organizations to collect and share data on infected patients and trace those who had come into contact with them. State government health officials also initiated emergency steps to share information on a daily basis among actors involved in stemming the crisis. After two months, the virus was contained in Nigeria and the country declared Ebola-free.
Several of society’s greatest challenges — from addressing climate change to public health to job creation — require greater access to data, more collaboration between public- and private-sector entities, and an increased ability to analyze datasets. This relationship between data and public benefits was vividly demonstrated in case study after case study at the recently concluded Cartagena Data Festival.
Yet for all the potential, a limiting factor is that much of the data valuable for solving public problems actually resides within the private sector — for example, in the form of click histories, online purchases, sensor data, and, as in the case of the above example, call data records. Amid the proliferation of apps, platforms and sensors, data on how people and societies behave is increasingly privately owned. We believe that if we truly want to leverage the potential of data to improve people’s lives, then we need to accelerate the creation and use of “data collaboratives.”
The term data collaborative refers to a new form of collaboration, beyond the public-private partnership model, in which participants from different sectors — including private companies, research institutions, and government agencies — can exchange data to help solve public problems. In the coming months and years, data collaboratives will be essential vehicles for harnessing the vast stores of privately held data toward the public good.

Examples of data collaboratives
Recent years have witnessed a rapid growth in data collaboratives. Examples include the following:
- In January 2015, the Obama Administration unveiled the Precision Medicine Initiative, a new model of patient-powered research and engagement that aims to build a knowledge base for individualized medicine. Specifically, the Initiative builds partnerships that enable it to include data from a number of existing research cohorts, patient groups, and private-sector labs to expand our understanding of cancer genomics and eventually allow for treatments tailored to individual patients’ genetic profiles.
- The Mobile Data, Environmental Extremes and Population (MDEEP) Project is a collaborative partnership between the United Nations University Institute for Environment and Human Security (UNU-EHS), the International Centre for Climate Change and Development (ICCCAD), Flowminder.org, Telenor Group and Grameenphone. Grameenphone, the leading telecommunications provider in Bangladesh, shares its mobile call data records to allow greater understanding of climate impacts by mapping population flows before and after extreme weather events.
- Founded in 2014 with a grant from Twitter, MIT’s Laboratory for Social Machines seeks to analyze networked, social data to measure and improve learning outcomes, help governments better assess citizen needs, and improve our understanding of how information travels in the public sphere. Crucially, Twitter’s contribution consisted not only of $10 million in direct funding, but also the granting of full access (via Twitter-acquired social media aggregator GNIP) to its complete corpus of public tweets.
The value of data collaboratives
These and other examples have many insights to offer about the value (potential and realized) of data collaboratives. At the GovLab, we have identified the following benefits — all contributing to the broader potential of improving people’s lives:
- Data-driven decision-making: In an information age, data from a wide variety of sources (private and public) is critical in enabling policymakers and other decision-makers to address major societal challenges. For example, Californian urban planners make decisions regarding the distribution of water resources by relying on models that help determine water availability and use data to adjust agricultural and commercial practices accordingly. Their decisions are guided by data and analytics tools from numerous sources, including Intel, the Earth Research Institute at the University of California at Santa Barbara, and the World Food Center at the University of California at Davis. Ultimately, it is the collaboration of expertise and data from these various sources that will help determine the success of the state’s water use strategies.
- Information exchange and coordination: Data collaboratives also add value by creating important platforms for information exchange and coordination among data providers and users. A good example can be found in the realm of clinical drug trials. Until recently, a substantial amount of the existing scientific data resulting from drug trials remained in private companies’ hands, inaccessible to independent researchers and citizen groups who could have added insights about drug safety and effectiveness. But in recent years, a number of leading pharmaceutical and medical device companies — including GSK, Lilly, and Novartis — have started making their clinical study results available to outside researchers via a central website (clinialstudydatarequest.com). Since January 2014, over 10 pharmaceutical companies have provided more than 1200 listed studies.
- Shared standards and frameworks to enable multi-actor, multi-sector participation: Data collaboratives can also increases synergies within the data community (data collectors, data integrators, data policy experts and data scientists), facilitating the emergence of much-needed standards and frameworks to make data interoperable and useful across organizations and sectors. With data emerging from an increasing variety of sources, and being used by a growing diversity of actors, such shared standards are essential to unleashing the full potential of data.
Four critical accelerators for data collaboratives
Despite growing recognition of the potential benefits of data collaboratives, these new forms of public-private partnerships remain generally under-utilized as solutions for large, complex public problems. Part of the issue is their relative newness: there exists little systematic research or analysis to help us understand the best way to form and utilize data collaboratives. In particular, we have little understanding of the risks (including considerations related to data ethics) involved in the deployment of data collaboratives, and how to balance these risks against the potential benefits.
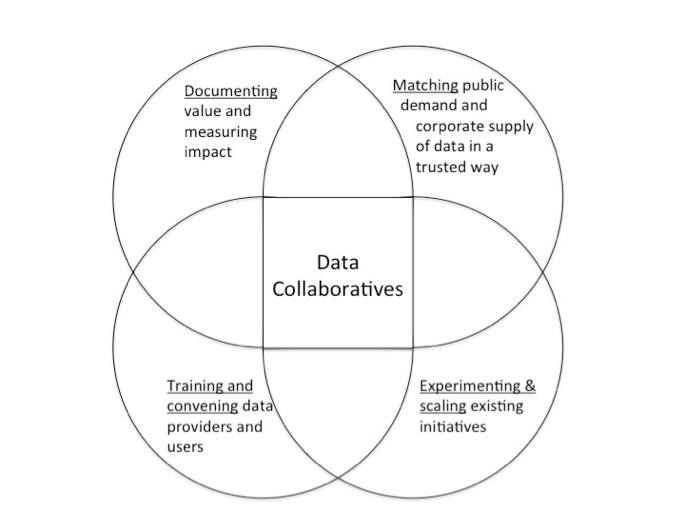
At the GovLab, we have been working to address the gaps in information and capacity surrounding the use of data collaboratives. Our work starts from the premise that a set of activities in the following four areas can accelerate the creation and greater deployment of data collaboratives toward solving complex social problems:
- Documenting value and measuring the impact of existing data collaboratives: Companies, governments and users need proof-of-concept in order to understand the value, practice and impact of data collaboratives. A repository of these case studies needs to highlight what works in forming these new partnerships — their value propositions, technical arrangements, legal frameworks, etc. — and strategies for measuring impact.
- Matching public demand and corporate supply of data in a trusted way: Data collaboratives require new governance mechanisms that will unlock the supply of private-sector data sets with potential public interest value. Such mechanisms must also include a system for filtering or prioritizing certain kinds of information and to ensure that the data being released actually matches public needs and demands. Without such systems, there is a very real risk that the potential public good of data could simply end up drowning in a virtual data glut.
- Experimenting and scaling existing collaboratives by leveraging new tools: Existing data collaborative experiments offer valuable lessons about what works and what doesn’t. Sharing and translating these lessons into a practical toolkit can help scale existing innovations.
- Training and convening data providers and users: Data collaboratives can only emerge out of a truly collaborative process. Bring together various actors from the data community, and providing a venue (virtual or physical) where data providers and users can build knowledge in an emerging field and co-create ideas and insights can help develop a movement around corporate data sharing. For instance, on Friday, March 20, 2015, the GovLab co-hosted the Accelerating Data Collaboratives Workshop, along with the National Institutes of Health (NIH), the National Oceanic & Atmospheric Administration (NOAA), and the White House Office of Science and Technology Policy (OSTP). This workshop brought together government agencies, companies, and experts to examine existing data collaboratives; document the value exchanges that take place through information exchange; and understand challenges and best practices in sharing public and private data for public good.
Four sets of questions in search of answers
The March 20 workshop, in addition to recent conferences such as NetMob 2015 and the Cartagena Data Festival 2015, are part of a first wave of convenings to engage a broader community to focus on how to develop new ways of collaborating and sharing data within and across sectors (with a particular focus on health, education and climate). While the workshop produced a variety of insights, we want to end here with some of the most important questions that arose from the workshop. From a research perspective, the following questions need to be addressed more systemically if we are to further the growth and development of data collaboratives:
- What different types of data sharing exist, and what are the pros and cons of each type? What kind of data collaborative is better suited for what kind of data use or demand?
- What sorts of incentives and value propositions lead businesses and nonprofits to decide to share their data assets? What factors must data owners weigh in making the decision to share?
- What are the risks of sharing data compared to the benefits, and how should data providers mitigate these risks? In particular, what are the risks to privacy and of unauthorized disclosures, and what specific steps — technical and otherwise — can be taken to minimize those risks? What data governance frameworks are needed to leverage the potential and mitigate the risks of data collaboratives?
- What sorts of data sharing solutions — APIs, data pools, or research partnerships, for example — are best suited to maximizing the public value of private data? Some companies donate data as a form of philanthropy, while others have shared corporate data through prizes and challenges, trusted intermediaries, intelligence products and other mechanisms. What are the respective roles — the relative benefits and disadvantages — of each of these mechanisms for data sharing?
Seeking answers to these questions is itself a collaborative enterprise. It will require bringing together technical, legal and security experts, along with researchers, industry and civil society groups to take a broad view of data collaboratives and the role they can play.
At the GovLab, we are committed to such a collaborative research enterprise (http://thegovlab.org/datacollaboratives/) and would be delighted to learn more if you have examples of data collaborative, any insights to offer, or answers to some of the above questions.
Please contact us at stefaan@thegovlab.org or follow us @TheGovLab and share your example of a data collaborative using the hashtag #datacollab.
Stefaan Verhulst is the Co-Founder and Chief of Research and Development and David Sangokoya is a Research Fellow at the GovLab.
